
Post-Terminalism: Why alpha will compete outside the Terminal
The paradigm shift giving rise to a new frontier

We saw in the last post that financial market data fuels a trillion-dollar industry peddling alpha. This ecosystem splits into two distinct camps: the buy-side hunters relentlessly pursuing alpha, and the sell-side enablers providing the tools for the chase. It’s a high-stakes game where one side lives or dies by their ability to extract value, while the other profits by feeding the frenzy.
Today's post focuses on the buy-side, which faces a perennial challenge: generate alpha or perish. Their survival depends on their ability to transform raw market data into investment gold. In examining this arduous journey, we’ll uncover the inherent limitations of the industry’s primary tool—the terminal—in supporting true alpha discovery. We’ll discover why the terminal’s domain ends precisely at beta, and why alpha generation offers an exciting opportunity that can upend the industry.
This opportunity represents a new value layer in the financial data stack, stemming from a fundamental capability that’s long been exclusively human: inference. The demand for efficient and fast inference requires us to move beyond the problems solved by the terminal, that of information access, into the frontier of intelligent insight generation. As we’ll see, this new value layer is inevitable, and those who play it right have the potential to dominate the financial data stack in the coming era.
Welcome to Post-Terminalism, a deep dive into how value is created after data leaves the terminal.
In Part 1, we’ll explore how alpha is derived from data and learn the role of the investment analyst and the nature of their existing research workflows.
In Part 2, we’ll examine the terminal’s original purpose as an information delivery system and ascertain any inherent constraints on its architecture and design.
In Part 3, we’ll understand how human inference has reached its limits to generate insights and identify the necessary building blocks to augment it.
Finally, in Part 4, we’ll investigate how emerging technology will bridge this gap and why this new value layer poses a unique opportunity for all.
Before we dive into the core analysis, a brief note on our expedition. This post examines AI’s impact on financial research through the lens of the terminal—the industry’s primary middleware1. Rather than detailing how AI will transform investment workflows, we focus on where and why opportunity exists. We’ll build from foundational concepts to market implications without predicting specific outcomes or delving into AI’s readiness. This analysis sometimes ventures into technical territory but don’t be deterred. These concepts are worth exploring as they provide the foundation and conviction for understanding a transformation that will reshape the financial data landscape. Enjoy.
Part 1
The Alpha Funnel
The most pressing challenge facing investment professionals today stems from alpha’s increasingly elusive and rarely persistent nature. Alpha—that coveted excess return—behaves like a mirage in the financial desert: visible to all yet attainable by few. While countless quantitative models and qualitative frameworks attempt to capture it, generating sustainable alpha first requires understanding the complete data-to-decision journey that creates it.
Consider the following transformation of Data as it journeys to Alpha:
Data → Information → Insight → Decision → Alpha

This value chain tells a compelling story from both directions. Working backwards, we see the genealogy of alpha: exceptional returns spring from superior investment decisions, which emerge from unique market insights derived from meticulously processed financial information, ultimately sourced from raw market data. The lineage is precise and unforgiving—weakness at any stage compromises the end result.
Looking forward reveals an equally powerful truth: the exacting and reducing mathematics of alpha generation where volume collapses at each stage. This isn’t a linear reduction but an exponential one—generating a single unit of alpha might require 10 correct decisions, built upon 100 distinct insights, drawn from 1000 types of information, which themselves demanded 10,000 raw data points.
This Alpha Funnel represents the successive concentration of effort required to progress through each transformation. The first stage—converting global raw data into structured information—is a monumental task that terminal vendors have mastered. But the critical second transformation—turning information into insight—falls entirely on the individual.
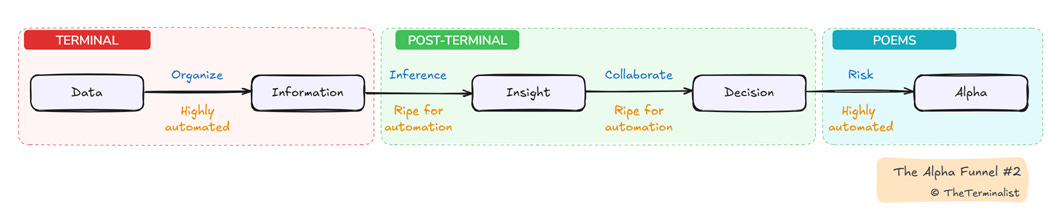
Herein lies the post-terminal distinction: data and information are commoditized system outputs stating facts that are equally available to all terminal users simultaneously. Insights, in contrast, are uniquely inferred from information and specific to the user who inferred it. Thus anything widely distributed becomes information, leaving anything personally inferred using individual judgment to become insight.
This bifurcation forms the cornerstone of our post. Terminals excel at delivering data and information (precursors to beta) but cannot generate insights (precursor to alpha). The terminal’s domain ends precisely where the alpha journey begins—making it structurally necessary but operationally and functionally insufficient for the needs of the modern research analyst.
That may seem controversial until we examine a real-world example that brings this distinction to life.
The Vagaries of an Analyst
How does an institutional investor transform market information into investment decisions? Let’s follow a research analyst at a US-focused equity fund who encounters a headline on their terminal: “Company X Announces Breakthrough in Renewable Energy Storage.” How is this development evaluated as an investment opportunity, and what role does the terminal play?
The terminal delivers the initial datasets—the headline, the complete article, related news across the company and sector, historical and current stock performance, detailed financials and related research. Yet this represents merely the starting line. Access to comprehensive information doesn’t automatically lead to investment decisions. The terminal presents facts without opinions, views, or insights—these must be independently developed through analysis and judgment.
This is where the analyst’s expertise becomes essential. The headline triggers a cascade of critical questions requiring deeper investigation: How does this breakthrough compare to competing technologies? What’s the defensibility and longevity of the IP? When will it reach commercialization? How will it impact financial performance? What signals are management and other analysts sending? What has the market priced in? How might competitors respond?
These questions rarely have straightforward answers, and many require information beyond what the terminal provides. Some demand access to specialized or proprietary information sources. Others necessitate new primary research or synthesis of diverse secondary sources. The most nuanced assessments draw on the analyst’s accumulated understanding of the company, sector, and technology—knowledge built from years of studying financial reports, scientific journals, independent analyses, and industry publications.
This glimpse into the analyst’s process, which we’ll explore more thoroughly in Part 3, already reveals:
Sources extend well beyond a single terminal ecosystem.
Triggers can originate outside the terminal environment (through alternative data sources, human networks, external events, or conversations).
Idea development requires transforming initial triggers through analytical expertise into comprehensive questions that must be answered.
We can also infer that the investment process involves some additional considerations:
Investment memos can consolidate all research centrally and can take various forms and file formats.
Idea validation requires alignment with firm investment policies and criteria through extensive non-terminal workflows—committee meetings, calls, emails, and offline discussions.
Asynchronous updates continuously reshape the investment memo as the analyst progresses through idea generation, development, and validation, incorporating new triggers, team input, and emerging information non-linearly.

Plenty for an analyst to handle who quickly confronts a sobering reality:
Inferring insights is complex. The process is multi-workflow, multi-channel, multi-modal, multi-source, multi-app, multi-party and sometimes even multi-terminal!
In this cacophony of inputs, the analyst becomes the reluctant conductor of an increasingly unwieldy orchestra. And this adds to the tension.
In addition to orchestration (running the process), the analyst must perform their true value-adding role and infer alpha-generating insights.
From the analyst’s perspective, this creates a dissonance:
I'm not paid to be a conductor; I'm paid to research and find alpha. Much of my workflow starts after information arrives on my terminal. I'm a post-terminal being in need of post-terminal solutions. Tools that go beyond relaying information and instead help me infer insights while reducing my orchestration load.
Eventually, the hard truth emerges: the terminal, just one input in a complex process, cannot and will not infer insights, leaving it fundamentally unoptimized for idea generation or opportunity identification—the very activities that accelerate alpha discovery.
Remarkably, despite the clear need, no purpose-built tool exists to address these requirements. The multi-dimensional challenge has long proven impossible to build for. This gap represents our identified problem space.
To fully appreciate this opportunity, we must first validate why the existing terminal solution cannot bridge this divide. Let's examine what terminals were really designed to do and why they fall short of addressing the insight generation challenge at the heart of investment research.
Part 2
Distribution's Purpose: Accessing Information
Distribution in the financial data ecosystem serves two critical roles.
First, it transforms raw data into meaningful information through the invisible machinery that forms the data processing and operations core. This sophisticated infrastructure encompasses ingestion feeds, data enrichment loops, storage systems, networking protocols, and real-time infrastructure (representing the aggregation and transformation stages we explored in the Smiling Curve).
Second, Distribution provides the environment through which users interact with and interrogate this information. This happens via the delivery stage and end-user application, commonly known as the terminal—the interface most professionals recognize as their window into the financial world.
The typical user, however, remains largely indifferent to the complex mechanisms operating behind the scenes. To them, the terminal represents a unified access layer that fulfills a seemingly straightforward request: Show me the world's financial information, and give me the tools to find what I need.
This deceptively simple expectation conceals the extraordinary complexity occurring behind the screen. Complexity that is solved with precise design, architecture and philosophy. One that represents an engineering marvel in the information domain, but ultimately prevents it from climbing up the alpha funnel toward insight generation.
The Machinery
The machinery behind financial terminals is where the true magic happens—an intricate ecosystem of hardware, software, and data operations that transforms raw market data into meaningful information for consumption (the ticker plant we saw at the end of Bloomberg's 7 Powers is a good example of the sophisticated machinery)
At its core, this machinery serves a singular purpose: to deliver the latest financial updates with pinpoint accuracy from source to user with the lowest possible latency. This goal demands a system that operates with military precision. The architecture achieves this through highly scripted processes where nothing is left to chance. Every step is meticulously defined, every hand-off rigorously recorded, and every process, pipeline, protocol, and policy extensively documented and programmatically executed—even when humans remain in the loop. Transmission and processing latencies have been already been engineered and iteratively reduced to global minimums.
The data handling logic—the complex rules governing how raw data transforms into usable information—has been fine-tuned over decades and encoded digitally. As errors and edge cases emerge, solutions are developed and immediately incorporated into the system codebase. Every data point follows a predetermined journey from its source, through the processing machinery, to its final destination on the user's screen.
What distinguishes this architecture is its fundamentally rule-based nature, governed entirely by explicit programming. The system permits no random walks, no arbitrary decisions, and no probabilistic outcomes. The machinery isn't designed to think, reflect, apply judgment, or evaluate meaning—it exists solely to execute with maximum efficiency, optimized for high refresh & fast response.
Like precision manufacturing equipment, financial data machinery operates with exacting standards. Like a factory floor, it cannot tolerate unplanned, random, or unknown inputs. Even minor deviations can trigger massive ripple effects throughout the system, so the data supply chains are meticulously engineered to ensure everything correctly arrives before processing begins.
This strict governance extends to all supporting data assets. The entire ensemble of data ontology—taxonomies, identifiers, formats, metrics, definitions, and metadata tags—is designed to be universal and fixed. Exchange feeds maintain consistent structures, corporate actions follow established patterns, and financial instruments like options, bonds, futures, and derivatives adhere to specific schemas. The machinery is built expressly to ingest structure, transform structure, and present structure.
Perhaps most notably, this machinery operates continuously on a 24/7 basis without requiring user input, functioning as a push mechanism that delivers information to terminals regardless of whether users actively need it. This pushed information flows indiscriminately and equally to all users—a powerful firehose of data that necessitates control mechanisms to allow users to safely consume what they need through a complementary pull mechanism.

The Terminal
The terminal serves as that pull mechanism, the sophisticated application layer that allows users to extract relevant information from the data firehose. Its primary function is to help users query and navigate the overwhelming flow of financial information.
Anyone who has used a financial terminal knows they are fundamentally command-driven interfaces. Regardless of the UI's visual polish, users ultimately rely on specific commands or fixed menu buttons to access the information they need. This command-led architecture underpins the entire user experience.
Navigation follows a strictly structured path that leads to self-contained functions or tabs. These tabs present information through various formats—text, tables, charts, and lists—that users can manipulate through filters, sorts, display options, and keyword searches. Every module is hard-coded with a singular purpose: fast response. Every aspect of the application is thoughtfully designed to eliminate loading or buffering screens. When a user enters any command sequence, the system delivers precise, predetermined, and pre-timed outcomes.
Like the underlying machinery, the terminal interface operates through explicit programming, with a fixed codebase determining exactly what happens for each user input and query. When users need to run complex queries requiring additional resources, extensive query handling logic coordinates these operations, calling specific functions, accessing required information, running calculations, and visualizing outputs. The codebase has been growing over decades to deliver sub-second interval results to any user command.
The user experience is deliberately uniform and carefully constructed. While different user segments may follow different workflows, no user receives exclusive access to features or information. There are no privileged tiers (though easter eggs exist2), hidden levels, or unexpected encounters. User access is universal. For the same fixed cost, a $100M fund analyst can work with precisely the same tools as the analyst at a $5B mega-fund. This equitable information distribution is in fact a cornerstone of the terminal's enduring value proposition.
The terminal delivers information synchronously to its global user base, with all updates arriving simultaneously. Importantly, the information presented on terminals is immutable. Users or other parties cannot edit, modify, or rewrite it. The data is not collaborative and doesn't need to reconcile its state across different terminal accounts. A user maintains strictly read-only access to all information flowing through it—a foundational and incontrovertible design principle.
The Philosophy of Information
The terminal and underlying machinery are optimized for deterministic outcomes and prescriptive conduct. Every possible result is known in advance, and every process to achieve that result is meticulously defined. This philosophy is encoded in the system's DNA, woven throughout its entire fabric, and embedded in every bit of its architecture and byte of its codebase.
Distribution's core philosophy can, therefore, be encapsulated as:
Deterministic, prescriptive, synchronous orchestration of structured, well-defined, immutable datasets for a universal, uniform, read-only user experience.
Though this formulation may seem unwieldy, each term carries significant meaning and precisely captures the terminal's essential nature. This careful definition reveals both the terminal's strengths and its inherent limitations.

While Distribution excels at fulfilling the user's primary requests—bring me the world's financial information, and give me the tools to find what I need—it fundamentally cannot address the critical next steps: tell me what it means, and what I should do about it.
This crucial gap demands a new task from the analyst: inference. This interpretive need requires an entirely different approach, one which we'll see completely contradicts the terminal's core philosophy.
Before we understand what constitutes inference, let's understand the analyst's role better, particularly their scope and expertise.
Part 3
An Analyst's Unspoken Burden
In our earlier example, we observed how a single headline triggered an analyst's exploration. But this raises an obvious question: how does the analyst decide which headline deserves attention among the thousands that flood their terminal daily? Why investigate a renewable energy breakthrough rather than "Company Z suffers slowdown in same-store sales across its declining UK footprint" or "JP 2yr yields rise to the highest level as inflation fears grow"?
Layers of Firm Context
The answer lies in specialization. At the professional level, investment analysts rarely operate with a global scope. Instead, institutional investors segment their focus:
by asset class: equities, fixed income, realty, commodities
by type: mutual fund, hedge fund, quant
by geography: developed vs emerging markets or country-specific
by style: value, growth, momentum, low volatility
by size: micro, mid, mega caps
by strategy: long-short, merger-arb, target-dated, etc.
These specifications create what we might call firm context – pre-baked filters that narrow the investment universe. It fundamentally shapes the triggers and how analysts explore, develop, and validate their investment ideas. These parameters are formally codified in a firm's investment philosophy, policies, mandates, and methodology – creating a relatively static form of firm context (we'll call FC1).
Once a specific investment target is identified, the analysis extends beyond public information. They must evaluate it through the lens of internal intellectual property. This process typically involves quantitative review using proprietary models to assess financials against various assumptions, complemented by qualitative analysis leveraging internal research and experts. This creates a more dynamic layer of firm context (FC2).
After a thesis is developed, it must withstand scrutiny from the team, the portfolio manager, and potentially an investment committee. This collaborative process generates debates, discussions, and multiple memo revisions, all contributing to another layer of collaborative firm context (FC3).
The analyst, in essence, navigates through these multiple layers of firm context at different stages, from diverse sources, and with varying levels of importance. This intricate workflow rinses information against various sets of intellectual property (FC1, FC2, and FC3) to identify and refine potential opportunities. Ultimately, it is only through the analyst's ability to infer insight from this contextual matrix that the firm stands any chance of capturing alpha.

Convoluted Context Integration
While this example represents one of many approaches to investment decision-making, the fundamental tasks remain consistent across methodologies, even as their sequence and nature may vary. What's critical to understand is that this process is inherently iterative and non-linear.
Non-linearity is a feature, not a bug, and a necessary input for quality investment research. Market conditions evolve continuously, team members contribute new perspectives, and portfolio constraints shift—all demanding constant reassessment and seamless context-switching between disparate systems. Tracking the state of analysis across these fragmented tools creates an enormous cognitive burden that diverts attention from genuine insight generation.
The babel of technical infrastructure compounds this challenge. Firm context might reside in SharePoint as webpages or PDFs, internal research in PowerPoint, models in Excel, memos in Word, while team inputs are scattered across emails, chat platforms and offline conversation. These systems may operate in isolation, creating harmful data silos.
The fragmentation exacts a steep price. Investment professionals waste precious hours managing information across disconnected platforms rather than conducting substantive analysis. More troubling still, this disjointed environment compromises decision quality - critical contextual information gets lost between systems, and collaborative insights fail to integrate coherently into the investment process.
Now, imagine this inefficiency multiplied across an entire firm. With each analyst simultaneously pursuing multiple ideas at different stages of development, the information-to-insight conversion ratio suffers. The analyst's true value lies in generating alpha-producing insights, not in orchestrating processes—yet process orchestration has become a necessary but unavoidable tax on the traditional research workflow.
Why hasn't this problem been solved? The obvious answer is complexity. But this raises a deeper question: why is this particular complexity different from what terminals already manage? After all, terminals successfully abstract away enormous complexity in transforming raw financial data into usable information. With their substantial infrastructure, capital, and resources, why have terminal providers struggled to effectively address this frontier3?
The answer lies in understanding the fundamental difference between processing structured data and generating insights. While terminals excel at the former, the latter requires something far more nuanced: human inference—the cognitive process of drawing conclusions from disconnected and sometimes insufficient information.
Slow Inference: The Current User State
To truly understand the analyst's challenge, we need to examine what happens in that critical moment of inference when information transforms into insight. This neural alchemy might appear stubbornly resistant to technology's touch but can be deconstructed with the same tools AI scientists use.
Despite its synthetic nature, artificial intelligence draws its design from human cognition. This biomimicry is deliberately modelled after human mental processes. Terms like neural networks mirror the brain's interconnected neurons, while reinforcement learning replicates how we learn through trial and error.
AI inference follows this same pattern of biomimicry. Since both financial analysts and Large Language Models (LLMs) derive their value from inference capabilities, we can ironically illuminate the analyst's workflow by borrowing conceptual frameworks from AI. In AI systems, inference unfolds in two distinct phases: Pre-fill and Decode.
Pre-fill is the input stage where all necessary context is loaded into the LLM. A form of information assembly. When you upload a PDF to ChatGPT for summarization, you engage in the pre-fill phase.
Decode is the output stage where a prompt generates a meaningful response. A form of information synthesis. In the ChatGPT example, this is the summarized output the LLM generates.
This dual-phase framework maps elegantly onto the analyst workflow:
Pre-fill 1: where the analyst retrieves and parses firm context alongside new market information
Decode 1: where the analyst identifies potential investment ideas and formulates new queries to validate the idea
The queries are executed across relevant systems leading to:
Pre-fill 2: where the analyst collates and processes all the gathered responses to various queries
Decode 2: where the analyst synthesizes and identifies non-consensus insights from the research into a cohesive investment memo
The typical investment research process thus requires two complete pre-fill and decode cycles. But what technical challenges does each phase present?
Pre-fill: Retrieval and Parsing of Context
Traditionally, context retrieval and parsing have been manual processes limited by analyst capacity. Firms have attempted to streamline context retrieval by consolidating knowledge bases in centralized repositories on corporate intranets. Similarly, they've tried to simplify context parsing through analyst onboarding, ongoing training, and investment committee reviews.
Digitally capturing firm context artefacts—policy documents, internal research, portfolio mandates, and more—requires an ingestion mechanism capable of handling unstructured, loosely defined, and constantly evolving content. These materials appear in disparate formats with varying fields and dimensions. They change over time and incorporate firm-specific definitions, metrics, and metadata. Additionally, these documents often reside across multiple repositories, created by different users, and exist in perpetual flux through collaborative editing. Such flexibility in inputs files was impossible in traditional hard-coded environments dependent on explicit instructions and predefined structures. LLMs fundamentally change this paradigm (let's call this LLM capability, L1).
Once these materials are ingested, firm context must become query-able—not through finite, predefined command sets but via open-ended, natural engagement. Simply improving navigation and access proves insufficient; the system must extract, synthesize, and infer meaning for any query or prompt the user might pose. This capability remained beyond reach in the deterministic, prescriptive world of traditional financial terminals. Again, LLMs transform what's possible (L2).
Decode: Idea and Query Generation
Following the pre-fill phase, the analyst's primary role shifts to discerning market currents for non-consensus ideas. Within active investing, some degree of non-consensus thinking is essential for alpha generation—it's the foundational principle that differentiates outperformance from benchmark returns.
Generating these non-consensus ideas and their validation queries is essentially a process of discovery. This discovery depends on the analyst's understanding of markets and their ability to explore interlinked or independent thoughts non-linearly.
An analyst's market understanding manifests in two distinct forms. First is the persistent user context built over years—their domain knowledge. Second is the temporal user context that exists during the ideation phase. This temporal context functions like a cognitive cache, constantly evolving and accessible for quick recall. While this cache draws partially from the analyst's persistent knowledge base, it also incorporates continuously refreshing market information and adjacent content that supports new ideas, thoughts and triggers.
Though persistent context resists precise measurement, an analyst's temporal context leaves digital fingerprints—information access history, data retrieval patterns, query logs, workflow patterns, recently accessed files, modelling frameworks, and variables employed. These digital artefacts sadly remain trapped in siloed, non-communicating systems. Manually ingesting, cataloguing, and integrating them across sources would be prohibitively slow and complex. Traditional terminals spent decades building machinery to stitch raw data from hundreds of sources, but new tools lack this luxury of time. LLMs fundamentally change this equation (L3).
Non-linear, randomized exploration is essential for idea discovery. Were the process linear and deterministic, it could be algorithmically encoded for automatic idea generation. Instead, non-linear exploration creates unique user journeys that yield personalized experiences and hence, uncommon outcomes necessary for non-consensus insights.
This non-linearity can be digitally facilitated but requires rethinking how information is accessed. In the traditional terminal environment, randomness is absent—each login presents the same pre-selected layouts and filters. This consistency inadvertently channels users toward identical information sets, views, workflows, and ultimately mental connections and ideas. While this predictability serves monitoring tasks well, it severely constrains idea generation. Shifting from rigid navigation structures to open-world exploration represents one approach to reimagining the research experience4 —a transformation LLMs can enable (L4).
Breaking down an investment idea/hypothesis into testable queries demands a multidisciplinary approach—combining associative, inductive, deductive, interpretative, and lateral thinking. This cognitively demanding activity represents the analyst's unique value contribution. While traditional applications cannot assist with this reasoning process, LLMs can meaningfully augment it (L5).
Like pre-fill, the decode phase remains a manual, labor-intensive process constrained by individual analyst capacity. Without appropriate tools, neither speed nor scale can be achieved within the confines of a single analyst.
Once idea and query generation concludes, another pre-fill and decode cycle begins. Having examined the first cycle in detail, we need not elaborate further on the second.
The Philosophy of Insight
The two stages of inference reveal why terminals aren't suited for insight generation.
Pre-fill demands flexibility with co-mingling unstructured and structured inputs - Terminals can't ingest the messy, evolving firm context that lives across emails, documents, and collaborative workspaces. Their rigid architecture requires predefined data schemas that can't adapt to the fluid nature of institutional knowledge.
Decode requires probabilistic, non-linear exploration - The rigid, command-driven interface of terminals forces linear navigation through predetermined paths. This fundamentally constrains the creative, associative thinking needed to generate non-consensus insights.
In essence, addressing this new value layer demands:
Non-deterministic, adaptive, asynchronous orchestration of unstructured, loosely defined, mutable datasets, that deliver a personalized, unique, write-also user experience.
The polar opposite philosophy of terminals. The terminal's architecture—brilliant for its intended purpose—becomes its greatest liability when confronting the inference challenge. It's not just that terminals haven't solved this problem; it's that they cannot solve it.

This brings us to a profound realization: Post-Terminalism requires an entirely new platform built on purposeful architecture and design, enabled by the transformative capabilities of Large Language Models.
Part 4
Fast Inference – The Future LLM-augmented State
To avoid falling into the trap of AI hype, I'll explain in the least technical way possible how LLMs perfectly address the gaps in our current investment research stack using some of the capabilities we identified in the last section (L1 to L5)
L1 - LLMs can ingest unstructured, loosely defined data across virtually any format and make it instantly query-able—without pre-processing or fixed instruction sets. Documents, spreadsheets, presentations, and emails—all become accessible through a unified interface without the months of integration work previously required.
L2 - they enable an entirely new form of engagement. No longer are users constrained by fixed menus or limited commands. LLMs can interpret an infinite variety of user inputs and successfully infer intent, making technology adapt to humans rather than forcing humans to adapt to technology.
L3 - beyond just ingesting diverse data formats, LLMs excel at stitching together relationships and meaning across disconnected datasets. With even minimal ontological guidance, their inference quality improves dramatically, creating connections that would take analysts weeks to manually establish.
L4 - LLMs introduce beneficial randomness into the research process. No two interactions follow the same path when engaging with an LLM as probability-based token generation creates natural diversity in responses. LLM-powered interactions represent the first time in computing history where information comes to you rather than you navigating to information. This fundamentally changes design considerations, freeing us from the navigation-based paradigm that has unconsciously trapped many products.
L5 - and perhaps most importantly for investment research, LLMs demonstrate increasingly sophisticated reasoning abilities with each new release. They can follow complex logical chains, make inferences across domains, and generate novel connections that mirror human analytical thinking (as demonstrated by DeepSeek to much fanfare).
LLMs have shattered the paradigm of explicit programming that dominated software development for decades. For the first time, we can orchestrate complex multi-step processes (L1 to L5) without coding each instruction. This capability alone transforms what's possible in the investment research workflow5.
Additionally, the order-of-magnitude collapse of time between information and insight changes how alpha can be discovered. This statement, while understated, is the most critical enabler of Post-Terminalism, and is what the post hinges on. If it had to be represented as a diagram, the following would only partially do it justice as it captures scale improvement of only two dimensions – volume and speed.
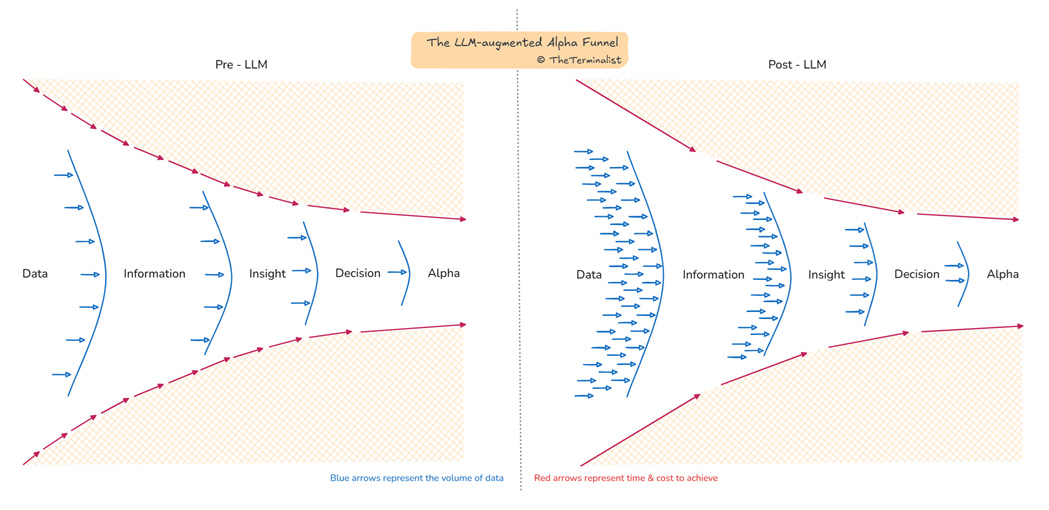
LLM implications extend beyond inference-heavy workloads. They could transform earlier stages of the alpha funnel, revolutionizing data extraction and information processing. As accuracy improves and error rates decline, LLMs open an intriguing Pandora's box of possibilities for sourcing financial data directly6.
To be clear, we make no determination on the readiness of enterprise-grade LLM solutions. It most definitely isn't. Randomness is a double-edged sword. One that can kill swiftly if incorrect, particularly with financial inference. But it is by no measure a good reason not to understand, explore and embrace its potential. It is a known unknown, and the unknown is increasingly being tamed.
For new entrants aiming to build a modern investment research stack, the path forward benefits from building on first principles without legacy constraints. More importantly, the stark polarity in requirements creates a legitimate opening for innovation. Startups are already tackling individual pieces of this new paradigm, and while they may start small, those with both the right to play and the right to win deserve further attention. Let's explore how the right to win can be accelerated.
The Innovator's Dilemma vs the Disruptor's Wedge
The competitive landscape for this new insight layer presents a fascinating opportunity for disruptors. While incumbent terminal providers possess vast capital reserves, they face a monumental challenge: building an entirely new interaction layer from the ground up. This isn't merely an enhancement to existing systems—it requires fresh architecture, different design philosophies, and new technology stacks.
Traditional vendors can't simply repurpose their existing codebase. The deterministic, push-based information model that powers terminals is incompatible with the probabilistic, inference-driven approach needed for insight generation. This architectural mismatch creates a classic innovator's dilemma.
Beyond technical challenges, incumbents face a talent gap. LLM engineering requires specialized expertise that's both scarce and expensive—precisely the kind of talent that gravitates toward innovative missions with significant upside potential rather than staid corporate environments. Additionally, modern LLM development environments encourage rapid product iteration that traditional vendors aren't structured to support but are generally required to attract talent.
Perhaps most surprisingly, the incumbents' greatest asset—their vast repositories of market data—provides limited advantage if it can't be commingled with firm and user context effectively, without which augmenting inference-heavy insight generation is impossible. Sure, some terminal features allow the user to upload internal research and share common content, but the feature set around it for meaningful inference is absent.

The evidence of these structural challenges is quite visible. Bloomberg took an entire year to launch a simple news summarization feature, which the NYT described as 'rocky’. LSEG continues to struggle with organizational alignment around AI, unable to solidify leadership for their data and analytics division (which represents 60% of its business and has seen two division heads depart in three years). This isn't an indictment of their capabilities—it's a recognition of the inherent constraints facing globally critical market infrastructure providers.
While incumbents face an innovator’s dilemma, it provides new entrants the lead time to develop and press the disruptor’s wedge. But what form might it take?
One approach is to frame a potential solution as a platform rather than a simple application—an independent layer that better aligns incentives with the end customer. Such a platform could offer several compelling advantages:
Optimized data costs: As LLMs interact directly with APIs and data sources, usage costs could quickly spiral. Unlike a $30,000 terminal that pushes more data than users can consume, an independent provider could build its business model around controlling and optimizing data usage. A consumption-based model charging only for data pulled could deliver significant economic advantages.
Technology stack sovereignty: Most financial institutions are increasingly wary of terminal vendors' growing control over their workflows and expanding share of operational expenditure. A middle layer designed to share control with clients—through open-sourced components or extensive customization capabilities—would address this concern directly.
IP protection: A firm's context and user insights represent its most defensible intellectual property. Unlike traditional terminals, which aren't designed for individually-instanced-on-premise-deployment, purpose-built platforms could be architected to keep proprietary IP within the customer's infrastructure and specific to each user instance.
Multi-vendor data: Current distribution models lock firms into a sliver (sometimes singular) of vendors for all their data needs. This is sub-optimal as strengths vary across providers by dataset, and a large vendor can eat up all data opex. The market has long needed a model that enables seamless selection of the optimal dataset by use case from across multiple vendors. A platform with relevant switching adaptors can establish cross-vendor connectivity even if vendors don’t actively support it.
Marketplace enablement: Over time, such a platform could evolve into a full-fledged marketplace where specialized LLM providers sell their fine-tuned models directly to buy-side firms for specific inference needs. This would also foster an ecosystem of LLM specialists optimizing for various financial use cases, removing the need to rely on a few general-purpose providers.
With these counter-positioning strategies, the opportunity to build a new value layer has never been greater. The enabling tools—LLMs and modern development frameworks—are widely available, as are instructive design examples from adjacent industries.
Of course, this future won't materialize overnight. Many pieces must fall into place: data access agreements, sustainable pricing models, regulatory frameworks, licensing regimes, and some degree of incumbent cooperation. But my optimism isn't predicated on market currents suddenly accelerating. Instead, it stems from believing in a perennial market force that will relentlessly drive this opportunity forward regardless of structural barriers.
Alpha’s Velocity Imperative
Alpha grows more difficult to capture with each passing day. As markets become increasingly efficient, firms are engaged in an escalating arms race, pouring resources into three input factors: data, compute, and talent.
The data frontier expands relentlessly. Firms purchase ever more granular, specialized, and alternative datasets, hoping to uncover hidden signals before competitors. Simultaneously, they're investing in sophisticated computational infrastructure—advanced modelling techniques, pattern recognition algorithms, and machine learning pipelines—to extract meaning from this data deluge.
Yet a fundamental economic problem lurks: data and compute are essentially non-rivalrous resources. The marginal advantage diminishes rapidly once a dataset is widely available or a computational technique becomes standard. Any firm with sufficient capital can acquire roughly equivalent capabilities in these domains to their peers.
So what happens when you've maxed out your data and compute spend? You slam headfirst into the true bottleneck: talent. Talent whose capacity is constrained by the non-existent tooling for orchestration and inference to support their workflow.
The truth is that talent—the skilled analyst—represents the only genuinely rivalrous resource in the modern investment stack. Two firms cannot employ the same brilliant mind. The analysts and their unique workflow constitute a firm's cornered intellectual property. They don't need replacement; they need amplification through tools designed specifically for what they're paid to do: generate unique insights.
As alpha grows more scarce and firms exhaust their advantages in data and compute, the most aggressive alpha hunters will inevitably turn their attention to increasing alpha velocity—the rate at which valuable insights can be discovered. Augmenting the analyst workflow with the transformative power of LLMs represents the next great competitive battleground. And many are on the path.
Wall Street's hunger is insatiable when chasing returns, and this institutional imperative for alpha will move us all to Post-Terminalism, willingly or otherwise.
The Race to be Post-Terminal
Terminals have dominated for decades and served their purpose admirably. But they were built for an era when information access was the primary challenge. Today's challenge is rapid insight generation in an information-saturated world.
A challenge that will be solved by Post-Terminalism - which will fundamentally reimagine how investment professionals interact with information to generate alpha and compress inference time to increase alpha velocity.
Slow inference will eventually lose out to fast inference, and traders of yesteryear will recognize how history could repeat itself. Ultra-fast inference (or pattern recognition back then) has long played out on the sell-side, stemming from a different tectonic shift - where unassisted human traders lost out to human-engineered algorithms. And that had a profound impact on the sell-side terminal business. Is the buy-side ready for a similar inflection?
As with all profound market transformations, change in financial data infrastructure will follow a familiar pattern: it arrives gradually and slowly at first, then suddenly and all at once. What begins as a ripple—AI-augmented research for sophisticated analysts—will eventually surge into a wave that can empower millions of wealth managers. The stakes are high; inference sits higher up than data and information in the value pyramid, and winning here could redistribute the balance of power across the Alpha Funnel.
Post-Terminalism has all to play for, and the next 10,000x opportunity is already taking shape, probably in a modest office far away from Wall St and 731 Lex.
If you're a founder building in this space, a venture capitalist seeking the next transformative platform, an incumbent operator looking to plan for this future, or an industry veteran looking to experiment, I invite you to connect. This future won’t be wrought alone, and in collaborating we improve the collective odds.
The Terminalist
h/t to Didier, Drew, Marianne and Ravinder for feedback on this post
Authors Notes
Ironically, Substack, a publishing platform, doesn’t let me know how many of you made it all the way to the end. So if you did, hit the like button or engage with a comment to let me know, lest I assume most of my writing ends up in AI pre-training.
Each post takes plenty of work behind the screen, and my machinery isn’t automated yet my content remains free. I trust it will be rewarded by the generosity of your shares, restacks and reposts.
As a preview of what is in the pipeline, I’d like to delve into how the terminal is slowly having it’s unbundling moment. I’d also like to pepper in some shorter posts on what the fascinating history of exchanges has to offer, and explore the theory of standardization that underpins the entire industry. But I’m very tempted to hijack it all with a post on LSEG given all the interest Matt Ober’s posts have been generating on LinkedIn. Let me know what excites you most, and I’ll try and sequence accordingly. And please reach out if you’d like to contribute!
Finally give me a follow me on X/Twitter for occasional short form highlights and quick takes - @theterminalist
This extends beyond the eponymous Bloomberg Terminal, including the recently retired Eikon, LSEG’s rebranding of it to the Workspace, Factset’s Workstation, Standard & Poor’s CapIQ, and a myriad other also-rans.
You’d be surprised by how quirky they get. Care to stare at a fish tank? Ted Merz put together a great list of lesser know functions, none unrelated to finance, inspired by Matt Ober’s post that generated a ton of answers in the comments.
Existing RMS (Research Management Software) products offers little solace to the user. What has come of Factset’s acquisition of CodeRed RMS, or LSEG’s creatively named House Views & Market Insights? Some RMS providers pass off portfolio analytics as their relevant tool, albeit one wonders how effective a monitoring tool is in idea generation. Others grab the RMS tag by providing tools for the investment manager selection and diligence process. Alas, the space isn’t well-defined.
A parallel industry example to consider is how Google's minimalist search bar design contributed to its triumph over Microsoft's elaborate, pre-loaded MSN interface that crowded the search experience.
This does not mean AI will replace the CIO, we are miles away from that scenario. But we are not miles away from AI augmenting the grueling analyst orchestration and inference load
Technically, this box is already open. Various innovators are aggressively reducing error rates and error materiality. Their ability to maintain these thresholds for extended durations as underlying models update frequently remains to be seen, but the signs are promising. It could be argued that once a high trust model is achieved, it’s all upside from there, and hence a worthwhile pursuit.
Super solid take, thank you! Cheers!
This work is a breath of fresh air in the era of AI slop on LinkedIn. I could quibble with some of the inconsequential points but it's a tremendously well-thought out post. Keep up the great work!