


10,000x. Bloomberg’s return and why financial data is so darn lucrative
An approximation of how data is turned into dollars

Edit: If you have been forwarded this post, just a heads-up, it is a 40-min read. If you prefer to receive it in bite-sized emails instead, just hit the subscribe button (it’s free), and I'll work something out for you by the next post.
Multi-baggers Only
The last post ended with a table of returns. Specifically, annualized returns for three firms that best represent the three stages of the financial data value chain. Here is how FactSet, CME and MSCI have performed since their IPO.

If you are used to dealing with numbers, you can tell that a 10%+ annual outperformance over the S&P500 is significant. But even a math wiz would struggle to calculate by how many times FactSet would have returned an initial investment in its IPO. CAGR calculations don't have a mental shortcut.
Despite our collective intelligence, the human mind has a peculiar blind spot. It simply doesn't grasp the power of compounding. It has nothing to do with our mathematical ability. Most of us can quickly work out linear math. We could, for example, work out quickly what 19 times 28 is. 19 is close enough to 20, so we can double 28 to 56, add a zero to 560 and reduce by 28 to get 532.
But what is 19% compounded for 28 years? We know it's more than 532%, or 5.32x the initial investment. But how much more?
15x? 25x? 35x? 60x?
The answer is 140x. Beyond comprehension. Our brain simply has no heuristic to solve long-term compounding returns.
FactSet has compounded at 19% for 28.5 straight years. An initial investment of $10,000 in FactSet at its IPO in Jun 1996 would be worth nearly $1.4 million today (year-end 2024). Let that sink in. A similar investment in the S&P 500 would be worth a tad over $130k. FactSet has outperformed the S&P500 by a factor of 10 since its IPO. TEN!
Is FactSet alone? What about the others in the financial data industry? Here's how a $10,000 investment in each of the nine listed peers performed since their respective IPOs up to YE 20241:

What jumps out immediately is the consistency. This isn't just one lucky company or a single brilliant strategy. We're seeing systematic outperformance across the entire industry. Every single company—from the century-old S&P Global to the relatively younger MSCI—has delivered returns that would make Warren Buffett raise an eyebrow
To avoid IPO bias - companies are in their relative infancy at IPO and hence have a low starting point from which to grow – let's calculate total returns from an acceptable reset point. A reset point like the Global Financial Crisis that rocked markets. From Mar 9, 2009, considered the low of the crisis, till the end of 2024, total returns of all nine stocks have again beaten the S&P500.
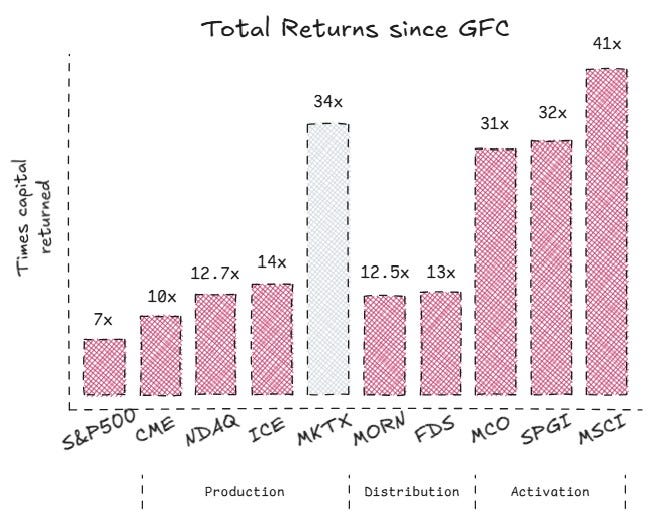
Even after stripping away the 'early days' advantage, the pattern is clear and compelling. What's also revealing is how the returns cluster by business model and stage. Production has returned 10-14x capital (for equities exchanges, we'll look at fixed-income exchanges and that disparity in detail another time). Distribution2 has had similar 12-13x returns. But Activation is in a league of its own at 30-40x returns.
The pattern continues when we look at newer entrants since the crisis…
CBOE managed a 6.7x return since 2010 vs S&P's 6.4x
Tradeweb delivered 2.3x since 2019 vs S&P's 1.2x
…and holds true even for firms outside the US
LSEG managed a 55x return since Jul 2001 vs S&P's 6.5x
DB1 managed a 14x return since Feb 2001vs S&P's 5.9x
This isn't random. When an industry consistently outperforms across different time periods, markets, and competitive landscapes, we're no longer in the realm of coincidence. We're looking at structural advantages that run deep.
How deep? Consider FactSet. From the last post, you'll remember that FactSet was 'caught in the middle' of the curve with softer metrics than CME and MSCI. But that comparison masked a broader truth. Against the entire S&P500, FactSet's 25% net income margin and 30% return on equity place it in the 85th and 92nd percentile of firms, respectively. Let that sink in: a company in the 'middle' of the financial data curve comparatively outperforms 90% of America's largest firms. That 140x return was well-earned.
Such clear outperformance raises three critical questions:
What creates such consistent outperformance?
Why does Activation generate more returns than Production and Distribution?
Are these advantages sustainable in an era of technological disruption?
For readers joining us for the first time, welcome to an investigation into how the financial data industry creates and captures extraordinary value.
Our analysis to date has revealed two critical insights.
First, we examined Bloomberg, the industry titan, uncovering seven pillars of power that make it nearly impossible to disrupt. We laid bare the foundational moats that build and defend value.
Second, we mapped the industry's structure through three distinct stages—Production, Distribution, and Activation. We discovered a smiling curve of power that bestows varying margins and profits to different market participants.
Today, we'll dive deeper into financial data itself. We'll uncover how the fundamental properties of financial data influence value creation, why certain business models dominate specific segments and identify potential disruptive threats or the lack thereof.
In deconstructing how data is converted into dollars, we'll uncover refreshing new perspectives that hopefully leave us more curious, energized, and better students of the financial data ecosystem. Whether you're an investor evaluating opportunities, an operator building competitive strategy, or an innovator seeking points of disruption, this analysis will have something for everyone.
We'll begin by first developing a mental model to guide our analysis.
Data to Dollars, an approximation
To understand how data gets converted into dollars, we can start with a working hypothesis. At its simplest, let's assume that at each stage, there is some input data to which some productive work is applied to create higher-order data.
We can simply encode it as:
Input Data + Productive Work = High Order Output DataThis high order data is a form of value-creation (even if the value added is as simple as sorting or categorizing data), so it can be further reframed as:
Data + Work = Value creationThis establishes that value stems from two sources: the data's inherent properties and the work applied to transform it. Data accrues value through intellectual property, while productive work arises from efficient capital investments into labor, software and infrastructure.
However, value creation does not simply translate to value capture. Two critical elements bridge this gap. One or more competitive advantages must defend the value created to protect it from being replicated or eroded. Additionally, converting that value to revenue dollars needs attractive and compelling commercials. We can express this relationship as:
Value Creation + Competitive Advantage + Commercials = Value CaptureIn our first post, we saw that the 7 Powers Framework was a great fit for assessing competitive advantages in the financial data industry. Doing away with the alliteration, we can reframe it as:
Value Creation + 7 Powers + Monetization = Value CaptureOr fully expanded out:
Data + Work + 7 Powers + Monetization = DollarsThese four factors - data, work, moats, and monetization - form our blueprint for understanding how raw information transforms into profitable insights. It's an intentionally simplified model that helps us decode a complex ecosystem into analyzable building blocks.
Before we look at each stage with this new lens, let's first break down the first variable, financial data, into its various components.
Data's inherent power
In the last post, we loosely classified market data through a binary tree of primary and derived data.
Primary data we saw took the form of raw financial data and is always tied to an instrument - a corporate bond, equity, option, futures, currency pair, commodity. Instruments are tradeable, producing price and activity data like volume and open interest.
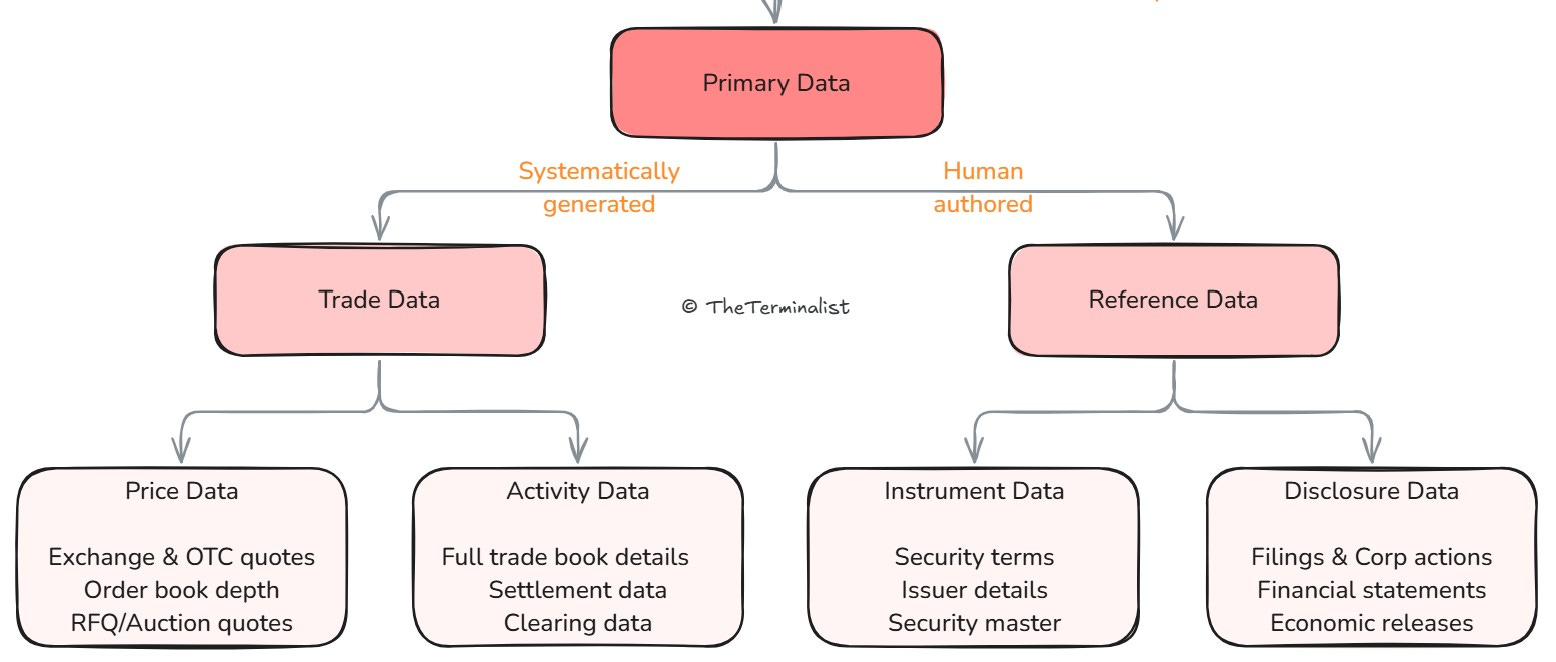
Price data originates as a time series - in micro-second blocks for most liquid instruments like stocks & futures or intra-day or indicative end-of-day quotes for illiquid bonds and funds. It can, hence, be either continuous or discrete. Time series data, by nature, is pre-organized, so price data requires minimal processing. Throughout our analysis, we'll use price data to represent all trade data, simplifying our framework.
Instrument data captures the fixed attributes of each instrument, like the ticker of a stock, the tenor and coupon of the bond, the strike of an option, the expiry date of a futures contract, and the unique instrument ID (symbology like ISIN/CUSIP). It sits within the realm of reference data.
Disclosure data encompasses two different streams.
Listed companies make corporate disclosures to their shareholders (referred to as fundamental data in the industry). This spans financial updates (quarterly earnings, annual reports, analyst call transcripts), capital allocation (dividends, debt issues, share buybacks, M&A), ongoing governance (board of directors, management, compensation) and operational updates (regulatory filings, patents). These disclosures keep investors informed and appraised of the value of their investments.
Public institutions make government and economic disclosures about each country's economy – labor (jobs, wage & unemployment data), GDP (quarterly and annual, real and nominal), price indices (CPI, PPI, GDP deflator), budgets (tax, spending, debt) and capital flows (balance of payments, FDI, FII). Additionally, central banks disclose money supply metrics (policy & interbank rates, reserve balance sheet, credit) and industry/academic bodies corral together manufacturing, purchasing and trade data. These disclosures inform investors about factors that influence investments in government debt and rates, currencies, and commodities.
That is all within the realm of structured reference data. For the unstructured realm, the curious can indulge in the footnote3. These examples collectively emphasize the complexity of the type and source of reference data and their heavily fragmented and disaggregated nature.
Both price and reference data are by-products of core business operations. Price data is produced as a by-product of trading activity on exchanges and quotes between market makers. Reference data is produced by companies and countries as a by-product of good governance while running a business/economy. Since the cost to produce is absorbed elsewhere, it appears primary data is created freely (unencumbered) and free of cost. It never depletes or degrades. In its origins, the two share similar properties. They diverge in ownership and monetization.
Price data is produced when there is an exchange of value, usually cash for a security. A centralized exchange attracts buyers and sellers, creating an environment where supply and demand naturally converge toward consensus prices. Prices are formed when bid-ask liquidity collides and finds a temporary equilibrium. Without a common venue to facilitate price formation, fair price discovery cannot happen. Enabling price discovery gives exchanges ownership rights over the price data produced, even though various market participants came together to create it. Data ownership rights give considerable market and hence pricing power, leading to CME, ICE & Nasdaq collectively generating $25 billion in revenue in their last financial year4.
Reference data differs from price data because it is produced as a public good. A public good has no meaningful ownership rights and cannot be monetized in raw form. What can be monetized is organizing reference data from various sources and making it accessible and available through a single end-point. The work put in is monetized, not the data itself. This is the domain of Distribution - aggregating, transforming, and delivering financial data from source to user.
Sustained work is required to maintain the data moat – quality, accuracy, completeness, timeliness, provenance, auditability, and trust. This data moat gives Distribution its pricing power and has led to Bloomberg, LSEG, S&P and FactSet collectively generating $20+bn in 'terminal' related revenue.
Derived data, the other half of market data, represents a fundamental shift in how financial information is created and valued. It forms when primary, reference, or non-financial data are combined and analyzed to create entirely new datasets.
Unlike primary data, which emerges naturally as a by-product of market activity, derived data is designed with intent, engineered with purpose, and structured for maximum value extraction. It grants full ownership rights to its creator, is valued for its intellectual property and can be monetized many times over. Derived data can be endlessly recombined and transformed, creating infinite possibilities.
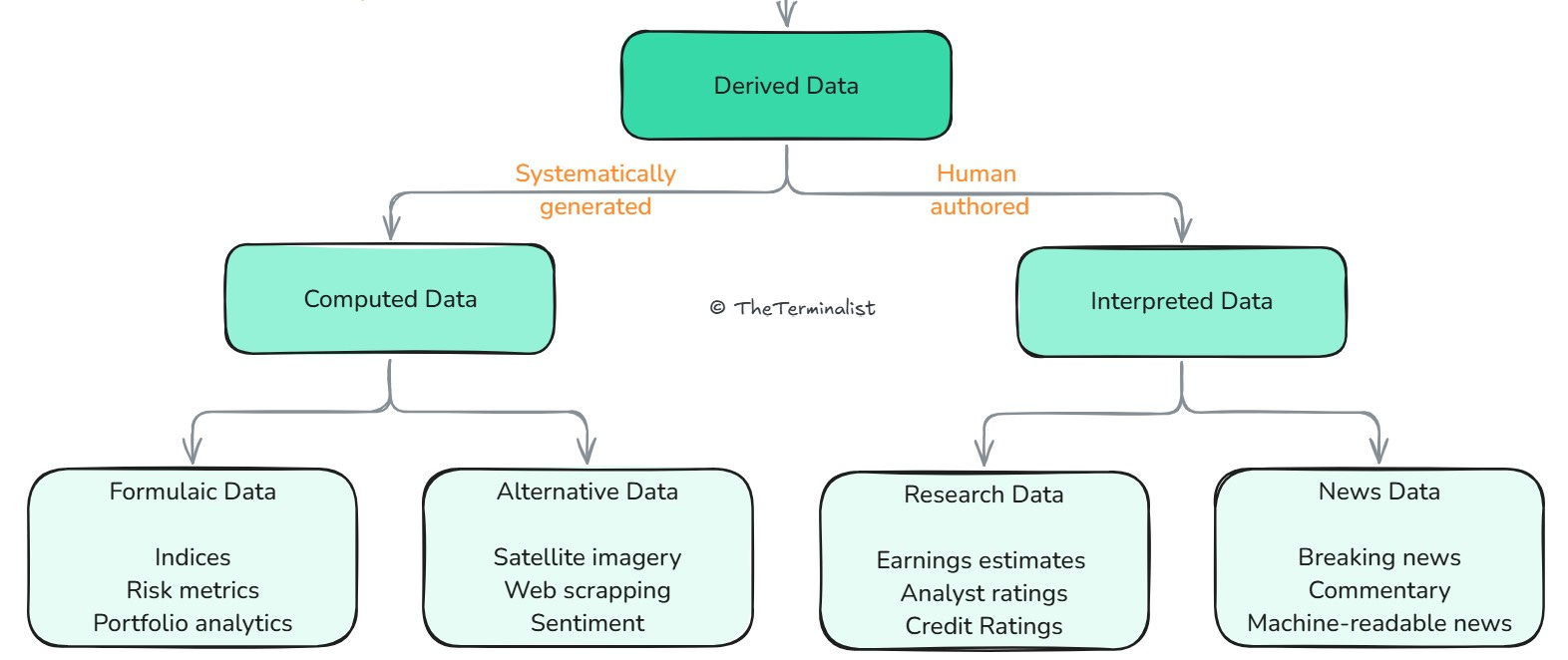
In the last post, we defined Activation as 'where information is analyzed and converted into proprietary insight'. We learnt that insights can be generated computationally or analytically. This lens splits derived data by the medium used to create it, computer algorithms or human experts. An example of the former is indices, and the latter credit ratings.
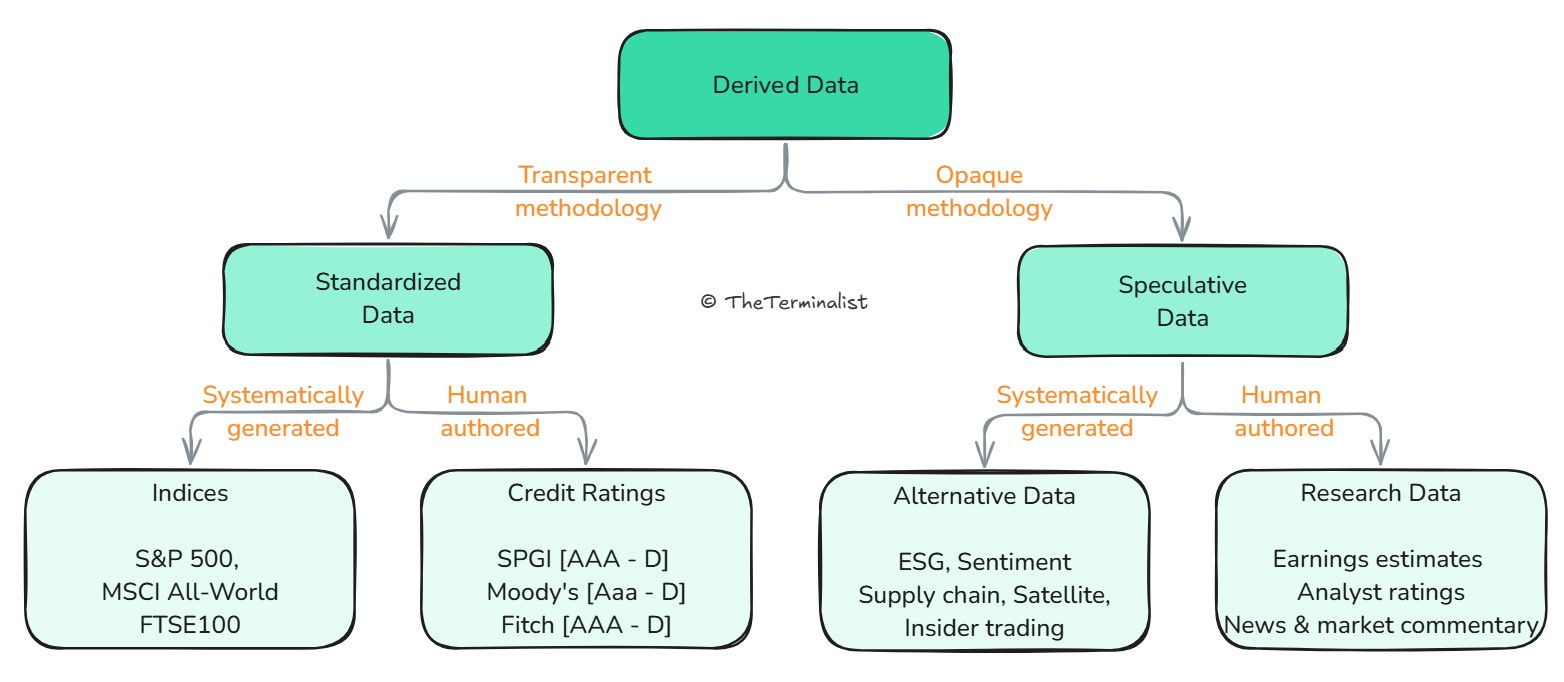
This classification was helpful as an introductory framework, categorizing datasets into neatly distinct buckets. But that classification hides an acute observation. Two particular datasets, indices and credit ratings, have both spawned multiple $1bn+ revenue companies, which the remaining datasets have not. To understand why, we need to split derived data another way, using the methodology used to create it – transparent vs opaque.
A transparent methodology accrues value as it can't be gamed, can't be discriminately and variably applied or can't be influenced by human bias. When insights are created by a pre-defined framework and public methodology, it can be easily verified and understood. S&P discloses hundreds of pages of its credit rating methodology, and MSCI, hundreds more on its index calculation. Transparency helps build trust, and trust drives large scale adoption in financial markets.
Large scale adoption also requires a few other ingredients. It requires the methodology outputs to be objective, universally legible, and consistently applicable to all investor types at all times. Eventually, this adoption leads to the formation of uniform, strictly defined and generally accepted global standards.
A global standard offers a form of measurement (like the metric system). In the quantitative world of financial data, measurement of performance and credit risk are paramount. Index providers and credit ratings agencies hence serve a common purpose. They offer the market an independent and standardized measurement of performance and risk. We'll call this standardized data5.
An opaque methodology, on the other hand, creates speculative data. Speculative data is subjective, not very legible (i.e. subject to varying interpretations), and inconsistent in methodology across vendors. The lack of transparency hinders it from attaining any global consensus across providers. Sentiment & ESG data fall in this bucket, as do analyst estimates, buy/sell ratings and most forms of alternative data (web-traffic, github stars). Without commonly accepted standards on how these should be generated, or consensus on how they should be interpreted or utilized, these insights remain speculative6.
Speculative data is valuable to a limited set of investors. Those who know to use it (1) profitably, (2) with repetition, (3) across market cycles, (4) and time horizons, (5) by data vendor. In the hands of some quants & hedge funds, who commingle it with hundreds of other signals and data sources, it can indeed be productive, i.e., generate alpha. For the rest of the market, it's either insufficient or unnecessary to the investment process and becomes, at best, table stakes. The TAM, hence, remains relatively constrained.
While derived data offers infinite possibilities for innovation, it grows in two distinct ways. Speculative data can expand both horizontally and vertically. Horizontal expansion creates entirely new categories – like the continued emergence of alternative data and even ESG. Vertical expansion occurs when providers differentiate on methodology to develop variations of established data categories.
Standardized data, however, can only grow vertically. The fundamental categories are already established: indices that activate price data and credit ratings that activate reference data (primarily financial statements and related disclosures). There's no room for further category creation since all primary data sources have already been activated. Instead, standardized data grows within each category – creating new indices for different markets/segments or new rating products for various debt instruments. This license to print new data into existence has led to S&P Global, Moody's & MSCI collectively generating $21bn in revenue in their last financial year.
Our binary classification of Derived data can now be represented along this new axis. We will continue to label it a loose classification as neither of the two are definitive and are adapted to help explain the market structure and its properties.
Financial data, whether price or reference, speculative or standardized, is varied and unique in size, form, and nature. It manifests in differing types, each possessing distinct properties and potential. However, without appropriate and sufficient work, data cannot fully realize its value. Having examined the data aspect of the equation, we can now analyze the nature of work required to create and capture value at each stage.
The Production Prerogative
(continued…)
We've established that only exchanges accrue value within primary data through the Production of price data. We also established in the last post that exchanges tend to be monopolies. So, we'll focus this section on exchanges alone and understand why price data is so valuable and why exchanges form monopolies.
Infinite data loops
Most large exchanges execute thousands of trades every second on each security. Every time a trade is executed, an exchange produces price data. These executed prices are aggregated into a feed and immediately sent back out to the market to inform all investors of the latest price. New prices trigger more trades, and as we saw in the last post, this results in a self-perpetuating cycle of price formation.
As every new price is a signal to the market, the market feeds off of live-streaming this price data in real-time. RT data is what drives markets. However, RT data is only valuable for the instant it was created. Then, just as instantaneously, it is relegated to the economics of delayed/historical data. This ephemeral nature of RT data necessitates a constant stream of access to stay informed. A vast majority of market participants - brokers, market makers, HFTs, quants, hedge funds, and active managers - survive by correctly interpreting and reacting to RT data. Low-latency, high-fidelity RT data is essential to the proper functioning of markets. Hence, it is the most sought-after form of price data and generates the most data licensing revenues.
Price data is also monetized by offering tiered access, serving distinct customer needs.
Delayed data serves participants who need to be informed but not necessarily react to RT price information - like long-term and passive asset managers and private and retail investors. By introducing a fixed latency (typically 15 minutes) to the price feed, the data's immediate value decays, resulting in significantly lower pricing, often free of charge for retail display7.
Historical or often EOD (end-of-day) data offers a permanent file of pricing data recorded at various intervals – from second-by-second to weekly to full-tick data of every executed trade. It caters to participants needing reference data for reporting, portfolio analysis, risk monitoring, and those who mine it for patterns and signals. It gets the moniker as it is made available at the end of each trading day.
Exchanges operate in a rather structured and orderly form. In fact, they are usually transparent on how everything works under the hood. Orderly trading creates orderly and structured price data. Exchanges then simply need to be pipe it out with minimal intervention.
Intervention is mostly unnecessary. Unlike the axiom in software, financial datasets don't have a 10x better version. Price data offers limited scope for improvement as all the factors of producing, recording and transmitting price data are already highly optimized. Producing good price data depends on strong liquidity, efficient order matching and fair market practices. Recording price data is a factor of accuracy and completeness, while transmitting price data is a factor of latency and resiliency (up-time). These factors don't offer room for 10x improvements for any mature exchange. Most efficiency gains have already been realized.
This creates a powerful data factory. The extraction of price data from exchange activity is entirely automated. No marginal work is required, so no marginal cost is incurred. Price data is at the peak of its fully attainable value. Since price data is created continuously, RT data will always be demanded. It sells itself ad infinitum, a guarantee of recurring revenue. Both delayed and EOD data are derivations of RT data and don't need specialized equipment; they just need precise mechanisms to extract and compile them. Once set up, they are all 'fire and forget' operations.
Price data also draws on its monopolistic position. It cannot be reproduced, reverse-engineered or replaced. While trades can be executed outside of an exchange, prices cannot be formed outside of it. All off-exchange trades are exchange-reported. In most countries, price data enjoys the freedom that comes with no threat of substitutes8.
In fact, it represents the fastest conversion cycle from data to dollars. Revenue from market data at ICE (owner of NYSE) has grown 8.6x over 14 years (2010 – 2023), far outpacing the 4.8x growth in transaction fees. A trend has plenty left to play out.
This seemingly perfect system of automated data creation and monetization raises an obvious question: why aren't more companies rushing to create exchanges? The answer lies in understanding the factors that make an exchange viable.
Exchanges are natural monopolies.
Exchanges are hard to create, even harder to disrupt, and impossible to displace. Most countries operate a single national exchange, and for good reason. The challenge arises from a catch-22 - liquidity. An exchange thrives on deep liquidity, as liquidity reduces bid-ask spreads, increases volume and enables orderly price formation. But liquidity is also zero-sum. Authorizing the creation of new exchanges is a deliberate act of splitting liquidity, which could result in higher trading costs, worse execution prices and increased information asymmetry. The competing exchanges would then serve investors less effectively, generating lower economic value and worse financial results - an escalating nightmare for any regulator.
In rare and carefully curated scenarios, more than one exchange can exist. One example is the US, the largest capital market in the world, which draws more liquidity than most countries combined. But even here, exchanges don't really split liquidity, they instead split by instrument type. So head-on competition is limited - CME dominates with futures, NYSE with the older industrial equities, Nasdaq with newer tech listings, CBOE with options, ACRA for ETFs and so on. Each exchange focuses on maximizing liquidity for its listed instruments, thereby serving investors better. Of course, this is only possible in countries with deep capital markets and sufficient instruments and volume9.
With the heavy regulatory and competitive disincentive, many exchanges, once established, enjoy considerable safety from disruptive competition. This safety allows it to focus on maximizing liquidity, efficiency, and cashflows - in that order.
Liquidity (aka depth of market) is the lifeblood of an exchange. As more buyers and sellers participate, more orders build up, reducing bid-ask spreads, reducing fees and producing higher quality price signals back to the market. Exchanges in modern tech parlance are dual-sided marketplaces (not of buyers and sellers, but of price takers and price makers), and as with all dual-sided marketplaces, they benefit heavily from network effects. A virtuous cycle that is impossible to reverse when it has been in effect for decades.
Efficiency is increased when friction is reduced. Friction takes the form of transaction fees and latency. Both have been in a death spiral to zero over the last two decades. Exchanges have encouraged and invested in their decline as they serve a dual purpose. Reducing friction attracts more liquidity, reinforcing network effects. Second, lowering fees makes it virtually impossible for new entrants to generate sufficient ROE10, while continued investments in latency reduction further add to the minimum capex to compete. To survive, nay welcome, such a precipitous decline in transaction fees, exchanges have optimized operating expenses too. Most have had decades to do so leaving little room for a new entrant to improve upon.
Once self-sustaining liquidity (critical mass) is attained through network effects and all efficiency gains are realized, scale effects take hold. Operating leverage quickly kicks in sending an increasing share of new revenue through to the bottom line. As capex wanes, margins and profits climb.

Cashflow excess offers another moat in case the regulatory shelter disappears. A moat that financially outmuscles new entrants. Excess cash (cash left after dividends and share buybacks) can quickly be deployed to acquire any credible threats. As we saw, head-on competitors rarely emerge. Instead, acquisitions are often used to expand into various adjacencies, with mixed results - e.g. ICE expanding into mortgage data, Nasdaq into risk & reporting software, DB1 into investment management software, and LSE into Distribution & Activation assets.
Winners, unsurprisingly, are first to the market. And they have significant staying power. You'd be correct to surmise that competing with an existing exchange head-on is suicidal. It's hard to get a license, improbable to attract liquidity, requires heavy capex to compete, with ROE/ROIC on the capex pushed to repulsive levels from declining transaction fees. There is no 10x improvement on the data or the service, and even if you manage to thread multiple needles, you would get showered in lawsuits by cash rich competition trying to nip you in the bud. It doesn't matter how noble your intentions were. Just ask Brad Katsuyama of 'Flash Boys' fame, who launched IEX to counter HFT scalping, reject co-location and provide investors with fair outcomes and exchanges with fair competition. Unfortunately, his valiant efforts to right the market's wrongs remain largely unrealized.
Alternatively, not taking an incumbent exchange head-on can provide an easier pathway. Opportunities to launch a new exchange are only attractive under a few conditions and appear rarely. Either there is an underserved customer segment or an unserved asset class. Both tend to occur when incumbents miss a technological shift. An example of the former would be the BATS exchange that launched to serve HFTs better, or further back, Nasdaq's launch 100 years after NYSE as the first electronic exchange better suited to cater to the new wave of tech companies at the cusp of the internet era. An example of the latter would be MarketAxess/Tradeweb, that launched to serve an increasingly digital fixed-income market, or Coinbase, which emerged to serve the entirely digital blockchain market.
In the rare instance a new exchange comes to market, it can capture outsized value. After all, Production's Prerogative is clear - a natural monopoly with an inexhaustible data feed operating on an instant value capture cycle. The pie can only grow larger.
Who will the larger pie attract next? What shifts, technological or otherwise, will spur the next slew of exchanges? How does increasing product financialization create opportunities? What asset classes or market segments yet remain underserved? What can digital assets teach traditional exchanges? Can exchanges increase profitability and investor protection at the same time? All worthy discussions this substack hopes to explore in due course. If you'd like to be involved or informed, subscribe to stay in the loop. And please share your perspectives in the comments.
The larger pie, increasing strength and number of exchanges only increase the complexity that Distribution stage participants have to deal with. As we'll see, this has its trade-offs.
The Distribution Dilemma
(contd.)
Distributors play a crucial role in the financial data ecosystem by aggregating, transforming, and delivering information from sources to end users. They deal with both primary data from exchanges and reference data from public sources. While primary data is structured and requires minimal additional work, reference data is complex and demands significant effort to organize.
In this section, we'll delve into how this complexity affects the three stages of Distribution and the meticulous work involved in creating value. All value creation in Distribution arises from the processing and handling of data, as third-party data itself holds no inherent value to distributors.
Before we examine this digital value chain of collecting, organizing and moving data, allow me to draw a parallel from an older industry firmly planted in the physical world - freight shipping.
A global shipping network needs ports and warehouses, efficient routing networks, quality control systems, standardized containers, customs & duty clearance, delivery scheduling, fleet management and last-mile delivery. This is quite similar to what distributors need for financial data – bulk ingestion points, data storage and networking infra, data validation protocols, normalization frameworks, data licensing and compliance, data sync & concordance policies, end-user interfaces and APIs.
The active contribution of the shipping industry is to sort the cargo, fit it into standardized containers, load it to available ships, and ship it to the correct ports, i.e. get stuff from point A to point B. For data delivery, the active contribution is to sort and categorize datasets, standardize them, match them to the usecases or queries that need these datasets, and get it across to the end user when it's called for. Without spillage, getting routed to the wrong port, being hijacked by pirates, being delayed by weather or any other troubles afforded to the shipping industry. Like the shipping industry, Distribution is first and foremost paid for on-time delivery performance with high accuracy and precision of the cargo being delivered.
However, unlike shipping, where physical capacity limits exist, data distribution runs into a different challenge - the complexity of cargo. While shipping standardized around the TEU container, financial data is diverse and lacks universal formats or standards. This actually makes Distribution's job harder. Let's unpack this complexity in more detail.
Complexity is not your friend
Distribution's real purpose and strength is organizing reference data. Reference data is chaotic and disorderly. We saw earlier how many sources and categories there are. Now consider how multivariate in features it can be - coming in various datatypes, formats, frequencies, schema, metadata, ingestion mechanisms - batch vs streaming, APIs vs SFTPs, etc. Then consider the curveballs that break the system - inconsistencies or errors from the original source, changes in fields as sources upgrade infrastructure, move away from legacy code or security policies, the list goes on. Each property introduces a unique complexity problem that doesn't have a scaling solution, especially when much of the Distribution middleware was built on legacy tech riddled with 'hard-code' practices. The only solution is additional human judgment and technical expertise to keep this all stitched together.
Now, that's just complexity at the Aggregation layer. In the last post, we saw what complexity at the transformation layer looks like - error correction. When data needs to be rinsed through various enrichment loops – collect, clean, sort, tag, categorize, concord, reformat, normalize – it introduces many avenues for error. We observed that both the enrichment and correction steps are also labor intensive.
For all their troubles in the prior stages, one would hope there isn't a complexity cost in the delivery stage - the final application that makes it available to the end user. Distribution, sadly, is not for the faint of heart. Here, the tax comes in the form of UI complexity. Unlike Production, Distribution needs unified end-points for users (machine and human) to interact with their diversity of data. Human users, being visual creatures, need an interactive front-end, a GUI (graphical user interface), or more commonly today, just UI. UI is a heavy tax hidden in plain sight.
UI capabilities seem harmless at first - tables, charts, feeds and filters to present the data. Want to filter all the FTSE 100 companies with revenue over £1bn? Not all that difficult. Wait, you want to use the filter across all major equity indexes across multiple markets, simultaneously? I'll need to join the different databases they sit on (they're all from different exchanges), each with varying file formats, schema, history and available fields and normalize it to British Pounds. Wait, you now want to filter both by raw data (revenue > £1bn & debt = 0) and derived data (P/E ratio <20 , 5yr EPS growth > 10%) for a custom date range? Hold on, I'll need to hook up enough compute to run the calculations on the fly, while joining my raw, derived and custom data keys with error-handling functions for when data is missing or negative. Wait, you also want to display the filtered results as a scatter plot with revenue on a log scale on one axis and the other as a double axis showing both absolute and percentage terms? Hold on, let me provision even more compute, develop the code logic to calculate and display all possible curves and plots, make them flexible to be switched around from drop down menus, and ensure I pre-calculate and store commonly used fields to reduce load times. Wait, you now want to add your custom portfolio data, share it with a client so they can annotate and collaborate on it real-time while maintaining private tenancy and data sharing restrictions between organizations? Hold on…

This UI example only scratches the surface. Financial data queries ripple through multiple layers - orchestration, logic, networking, storage, and compute - all of which must synchronize perfectly to prevent crashes. Users experiencing UI lag glimpse just a fraction of this complexity. Legacy systems compound the challenge: most distributors still run on monolithic architecture, dated languages, and traditional software development practices. Yet, somehow, Bloomberg's engineering team keeps the Terminal reliably fast despite the complexity under the hood. The $30,000 price tag is not unearned.
An equal measure of complexity exists in serving non-human users. The machine users are sensitive to volume, accuracy and timeliness, which present different challenges and are outside the scope of today's post. In either case, complexity at the delivery stage requires heavy engineering investments in software, hardware and coders who can bring it all together, adding to fixed costs from prior stages.
Margins, margins, top and bottom
As new datasets are sourced and new UI features are requested, complexity increases at each stage. Unfortunately, the cost to manage and address this complexity only accelerates. Distributor margins, gross and net, have been slowly eroding for 15 years. Beyond complexity-driven fixed costs, they also deal with higher variable costs and growing competitive pressures. Sigh.

While market data is an enterprise SaaS business, it doesn't come with all the enterprise SaaS metrics. Enterprise sales come with enterprise costs – localized sales, account management and customer support teams, long sales lifecycle and slow onboarding. But market data SaaS comes with additional sales & operational costs that say a CRM provider doesn't have to contend with-
Capital at risk means user issues need instant resolution, unlike CRM systems where day-long turnaround times are acceptable.
Support complexity compounds with urgency. Each issue demands deep expertise and longer resolution times, multiplying rather than adding to costs.
Deep integration with trading workflows requires rigorous testing and approvals given the capital at risk, dramatically extending sales cycles.
Complex UIs demand intensive onboarding and ongoing training. Unlike simple CRM interfaces, market data platforms have extensive shortcuts and functions across multiple workflows. This breadth requires specialist support teams.
System reliability is critical - while a CRM outage means delayed work, an hour without market data could mean permanently lost opportunity and millions in potential losses. Both vendors and clients invest heavily in redundancy.
So, while complexity in the A-T-D stages leads to fixed costs, complexity in sales & support leads to variable costs. The capex and opex add up at an enterprise scale, further underpinning the urgency to offshore labor, as we saw in the last post. An asset-heavy model incurs asset-heavy economics.
Like shipping, a pure distributor rarely owns its data, except when they control production or activation assets (like Bloomberg with fixed income data or LSEG through Refinitiv acquisitions). Without ownership rights - most third-party data isn't exclusive, and most reference data isn't unique - pricing power is limited to the value of the productive work.
The threat of data substitutes limits it further. As a public good, reference data is available from all major distributors. As automation costs plummet and LLM capabilities advance, smaller players can shortcut the painstaking process of extracting unstructured data and organizing it into usable information. Sure, no large customer is going to change vendors overnight. Trust takes years to develop. However, we are approaching a future where trusted reference data can be available not just from a few big providers but also from niche vendors coming together through data marketplaces.
Data marketplaces can empower small data providers, allowing them to optimize data extraction at the lowest cost for a specific dataset. By narrowing focus, they can reduce complexity, reduce overheads, price aggressively and achieve higher margins. These highly optimized vendors can go straight to the end client with the marketplace providing Distribution – a scenario that is already in play.
Solutions are also emerging to solve UI complexity while integrating various data providers into a single front-end. Built on modern, modular architecture, they offer flexible data wrangling and native LLM capabilities through open-source platforms. One such solution already has tens of thousands of users. IYKYK. Comment for a feature on startups of note.
These developments commoditize the application layer (delivery) and the extraction layer (aggregation). Total capex to achieve parity on both fronts with new solutions has undergone an order-of-magnitude reduction. The orchestration layer (transformation) may be the last to attract disruptive forces, but it still has some strengths to rest on. The rigor and reliability of harmonizing data, storage & compute across sources, clients, databases and CSPs still bestow trust to Distribution. Trust that supports 90%+ retention for a 90%+ recurring revenue business. But with margin pressure from all corners, Distribution's Dilemma is far from resolved.

Can transformation also be commoditized, and if so, does Distribution risk getting commoditized, much like shipping before it? Are the big four distributors equally threatened? Where can Distribution press their advantage? Can acquisitions offer a way out? Is it too late to expand into Production or Activation assets without attracting direct competition?
If any of these topics interest you, you know what to do. Get this post out to more readers, and share it with friends and colleagues. It takes me hundreds of hours to put together a single post, it takes but a moment to share it.
Activation advantage
(contd.)
In the last post, we learned how Activation is about turning information into insight. We briefly saw that the two main ways to activate data are through computational or analytical means. That is by applying proprietary methodologies algorithmically or through expert human assessment. The former gave rise to indices & the latter to credit ratings11, each spawning billion-dollar revenue businesses.
Proprietary methodologies generate proprietary insights that bestow intellectual property rights. IP rights form the backbone of data monetization. However, not all derived data is created equal; hence, IP rights are monetizable to varying degrees.
Independent reducing functions
Indices represent computational activation at its purest - combining price data from multiple securities into a single value that attracts more value than its individual components. The S&P500 index, for instance, captures significantly more value simply by adding and market-weighing its constituent price data, creating an almost effortless conversion from data to dollars.
Computational activation leverages both additive and combinatorial properties of structured data. With zero marginal cost to create new indices, providers can endlessly combine underlying datasets. Most combinations will prove worthless, so the payoff is neither fixed nor guaranteed. But index providers are happy to bear the cost of experimentation (the fixed costs of launching and scaling unsuccessful indices) since finding a winner has power law returns. Consider MSCI's mind-numbing 280,000 equity indices - 280,000 experiments to find the 50-100 indices that generate a majority of its revenues.
Ratings exemplify analytical activation. Like indices, it also derives value from being a reducing function12, distilling various inputs into a simple scale from AAA+ to D. But unlike indices, value creation isn't instant – it requires deliberated judgment. A credit analyst follows rigorous methodology and policies while applying expertise accumulated with years of experience. While this work has a cost, it bears no experimental risk. The process of arriving at the rating can be applied indiscriminately to any debt issuer for a fixed and guaranteed payoff each time.
In fact, every debt issuer pays to rate every debt issued, typically a tiny fraction of the total debt value. The fraction varies depending on the complexity and type of debt. While indices monetize by charging a micro tax on all investable assets, ratings monetize by charging a micro tax on all investable debt. Incredibly simple, incredibly powerful.
Their prevalence and commercial structure are no accident. Both indices and ratings serve as standardized measurements requiring independent calculation. This independence is crucial - asset managers and debt issuers can't credibly self-assess or self-certify. They need independent verification to attract investors, embedding guaranteed demand in the market structure. This structural requirement makes the service both essential and highly monetizable, though, as we'll see, also subject to abuse.
However, demand cannot be spread across multiple fragmented vendors. That would lead to conflicting measurement standards, failing the market's needs. Demand cannot be serviced by a single provider either. Redundancy is essential for critical services and avoids systemic failure risk. Like Visa & Mastercard, Apple & Android, Boeing & Airbus, ratings and indices naturally lead to semi-duopoly markets - Moody's & S&P for credit ratings, and MSCI & S&P for indices. To keep the antitrust regulators at bay, each pair entertain smaller rivals in Fitch and FTSE-Russell, respectively.
In indices, competition is carefully stage-managed at the fringes. The S&P500 doesn't have an MSCI equivalent. The MSCI World doesn't have an S&P equivalent. They each play in their lane. Competing indices are mostly in sub-scale or unestablished markets – riding temporary trends and edge cases that never accumulate any meaningful AUM. Unlike the other duopolies mentioned above, direct competition is studiously avoided.
In ratings, the opposite is done. Competition appears head-on but is entirely manufactured. Astonishingly, every debt issue is always rated by both S&P & Moody's. The demand comes to them, not the other way around. The dynamic is more powerful than Visa and Mastercard - sure, every merchant accepts both, but each transaction generates revenue for only one. In ratings, issuers voluntarily seek out and pay both providers to rate the same debt! Doing otherwise would be blasphemous.
The art of triple dipping
Such market structures create perverse incentives. For rating agencies, the 2008 crisis revealed how guaranteed fees and lack of competition eliminated incentives to scrutinize sub-prime mortgage risks properly. Index providers face different temptations - while their computational outputs can't be manipulated, the absence of direct competition enables aggressive price discrimination. As it's unlikely to cause a financial crisis, this price gouging remains largely hidden from public scrutiny, save for findings buried in the regulator's website and the brave exposés by groups like Substantiative Research.

The scale of price discrimination is staggering – clients paying between 13x to 26x for the same product - making Uber's surge pricing look charitable. But the real ingenuity lies in how these fees are obscured within the market structure.
Lets say you own the SPY ETF (tracking the S&P500) in your pension portfolio. Its nine basis point management fee seems tiny - just 9 cents per $1,000 invested. Of this, S&P collects 3 cents as licensing fees. The genius is in making individual fees appear negligible while extracting massive profits at scale. With AUM north of $600bn, S&P earns $180 million in asset-based fees annually from the SPY ETF alone, for what amounts to an excel formula. SPY isn't the only ETF mimicking the S&P500; Blackrock and Vanguard have similarly large ones too, adding at least another $100m in fees (unconfirmed). But the revenue stream doesn't stop there.
Your pension manager gets tapped too: first through index licensing fees for performance benchmarking, and again when they use index-based derivatives like e-mini puts for portfolio protection13. An infinitesimal fraction, nonetheless, these too go from your portfolio in the form of management fees. You, my friend, are scalped three times on the same dollar. S&P & MSCI do minimal additional work to create that revenue, and so as AUMs build, all your cents are just profits.
For ratings, there is a fee when debt is first issued and another fee for ongoing monitoring (markets and economic conditions change after all). The ratings are then repackaged and sold to investors who pay a licensing fee to access individual or aggregated ratings data across their portfolio of debt instruments. Another artful form of triple dipping - getting paid for the creation, maintenance and licensing of the ratings. A highly margin accretive practice.
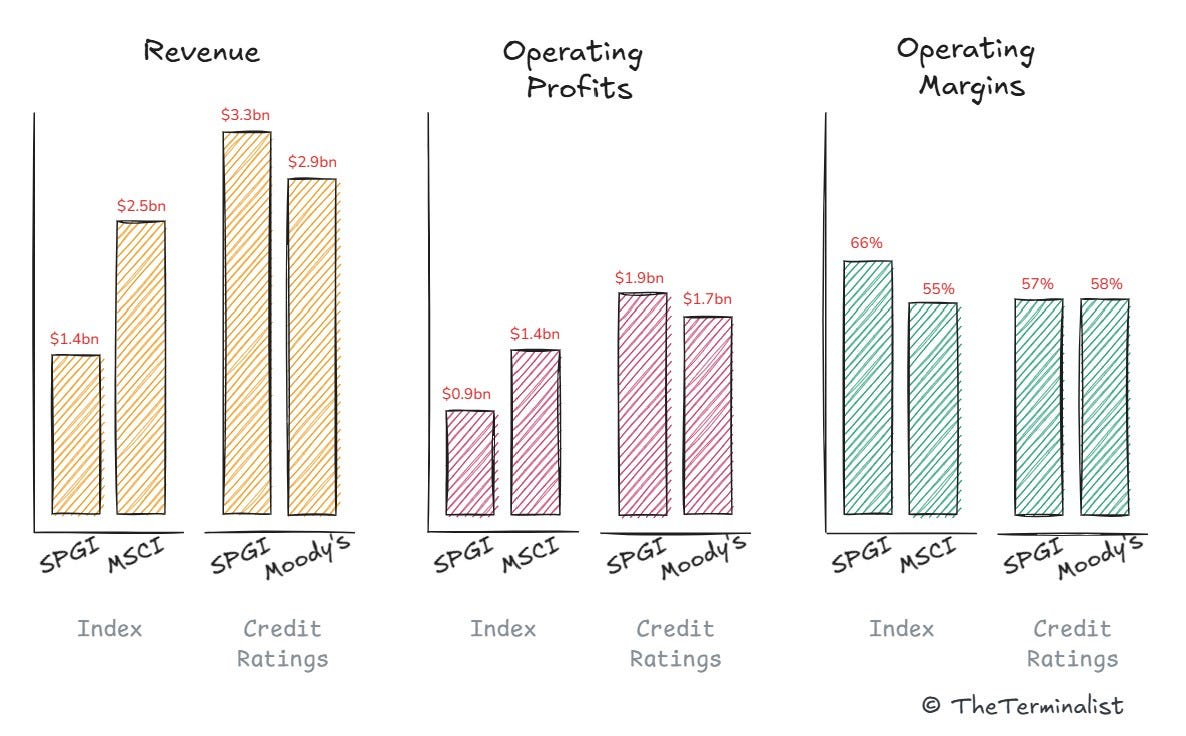
The industry's high margins and cashflows are fortified by multiple moats. Each new index or rating expands their proprietary data catalog, further cornering the resource and increasing pricing power. Network effects then draw new customers to established standards, a dynamic that has compounded for decades. Scale effects generate cash for acquisitions, with the big three dominating all global markets directly or through majority stakes in domestic players. It appears that the window for meaningful competition closed half a century ago. Activation's Advantage has only compounded.
But some factors of production are changing. Financial data is becoming more accessible and available. The cost of compute has dropped, and the cost of intelligence (i.e. human judgement) is on the precipice of dramatic change. These changes are empowering new entrants and enabling novel technological assets. The big three's recent acquisition patterns hint at their recognition that data isn't the only resource worth cornering - software and code increasingly matter, too.
What are these hints? What are the gaps in the armor of these impregnable businesses that new entrants can focus on? What shifts are incumbents slow or unable to adapt to? Why do mega-asset managers accept rather than challenge the status quo? Why haven't the regulators done more - are they toothless or straight-jacketed?
There is plenty to uncover at each stage. While I've uncovered some pieces of this puzzle, many remain hidden in the experiences of industry veterans. If you've had a front-row seat to product strategy, market-entry, acquisitions, or corporate intelligence, I invite you to share your (non-confidential) insights (anonymously, if you prefer). It'll help accelerate the quality and rate of analysis in this Substack tenfold. Drop me a message if you are interested.
Shovels and picks
Financial data has proven quite lucrative for all the companies we've encountered. 140x by FactSet is an incredible return. 740x by S&P, phenomenal. But there is one even greater.
Mike Bloomberg turned a $10m severance package into a $100bn+ fortune. A jaw-dropping 10,000x return. He built a financial data empire that straddles all three stages as he understood three core principles before anyone else.
Seize the means of Production – and secure an infinite data source
Distribution is king – so build the industry's default financial data OS
Activation empowers monetization – so develop proprietary data IP
He realized that all three stages offer a form of abstracting away complexity – Production abstracts away liquidity incentivization, order routing and matching mechanisms to produce a simple price feed. Distribution abstracts away the complexity of organizing reference data into an interactive interface, while Activation abstracts the complexity of standardizing measurements into globally accepted metrics.
Most of all, he realized that the market would pay to reduce complexity. Because the market has an eye on a much bigger prize. Financial data, you see, can multiply capital.
Consider that Jane Street cleared $14.2bn in revenue in the first three quarters of 2024 and Citadel Securities $4.3bn in the first two quarters. The two largest market makers alone are likely to rake in more revenue ($25bn+) than the big three exchange providers combined. BCG estimates investment banks (IB + Trading) cleared revenues north of $200bn in H1 2024. McKinsey estimates that the revenue of selected participants (those they could find on Google Search) of the North American asset management industry was north of $200bn. A back-of-the-envelope calculation of the $4.3tr global hedge fund market with a median management fee of 1.25% gives it $50bn in revenue (ignores the larger pool of performance fees).
Together, they add up to about $700bn in revenue across these customer segments. Factor in interdealer brokers, wealth managers, private equity and credit, insurance companies and pension funds, and you potentially have a trillion-dollar market in the pursuit of alpha. More accurately, a market that promises or facilitates alpha, as ironically, $1tr is earned even when no alpha is delivered.
The financial data industry is a critical enabler of the pursuit of alpha and the $1 trillion in fees it generates. Bloomberg presciently built his empire on the age-old adage,
When everyone is mining for gold, sell shovels and picks.
I suspect that the comparison to gold still has more to reveal about the industry. MRB may have been the first to generate 10,000x returns in financial data, but he won't be the last. His playbook, after all, is becoming increasingly evident.
Until next time….
The Terminalist
h/t to Luyi, Matt, Pete & John for feedback, and Ted for correcting what would have been a major faux pas. Thanks to Koyfin & Finchat.io for data and charts that made this post possible.
If you enjoyed this post, a great way of saying thanks is to repost on Substack, LinkedIn, Twitter or your internal corporate network.
Follow me on X/Twitter for occasional short form highlights - @theterminalist
Further Reading & Notes
Net Interest is hard to ignore for any student of finance. Marc has a great catalogue of backstories for all the major corporates in FS. Here are some interesting reads – ICE, S&P Global, exchange business
An interesting post on how HFTs and the race to zero latency can be seen in a different light. Also, an easy to digest explanation of NYSE vs Nasdaq by CJ.
If you don’t already, follow Ted Merz and Matt Ober on LinkedIn. They both provide frequent insights into the industry and adjacent markets. Ted’s recent posts on talent and tenure at Bloomberg are a first of its kind. Matt synthesizes key publications on his blog, most recently sharing his take on the State of Fintech 2025.
Some relevant headlines that caught my eye –
24-hr stock trading is around the corner; guess who is raking in more real-time fees? Of course, that also means more transaction fees as exchanges hit record ADV and contracts traded. Pay up, please.
Vanguard makes record cuts to its already low expense ratios, sending BlackRock’s shares 6% lower. Guess whose revenue growth is unimpacted by these fee cuts? Even Nasdaq’s index game is shining.
UK’s equities consolidated tape gets delayed to 2028, missing it’s chance to launch on the 50th anniversary of it’s US counterpart. Adds to some recent heat of how slowly regulations move on this side of the Atlantic.
After LSEG hitched its future on Microsoft in 2022, FactSet has recently tag-teamed with a nimbler, high-velocity option in Perplexity. Contrasting approach and philosophy, one that warrants further attention. Bloomberg, not to be left behind, is taking a measured(?) approach - launching news summaries a whole year after earnings call summaries.
At the other end of the replace-my-tech-with-Microsoft spectrum, a contrarian strategy that I expect will pay dividends is being pursued by the sharp folks at XTX Markets. Maybe worth a deep dive into why XTX is building their own data centers. Another own the means of production at play. I welcome a connect if anyone has contacts there.
New exchanges are getting funded – Blackrock, Schwab, Citadel & Jump – jump behind the new Texas Stock Exchange. Pincus got behind one from Miami. Will they be sufficiently differentiated to compete when new ATS are creeping in too, or are they just hoping for the rising tide to lift all boats?
Interesting and unrelated long-form content I’ve been reading:
Abraham Thomas with another incisive take on why venture works the way it does.
A fresh take on how LSE, the exchange, losing ground to the US, is a canary in the coal mine of UK policy making impacting competitiveness and talent.
There is no shortage of Buffet lore, but Frederik Gieschen’s obsession never fails to amaze. Here, he looks at a lesser known name Buffet admired.
Brett Scott’s cerebral pieces are hard to summarize into one sentence. I’ll leave you with the title - The Stone Soup Theory of Billionaires
SPGI, under its previous iterations, started trading in the depths of the Great Recession, listing in 1929. Prices from that date aren't readily available. In fact, even most paid providers (for retail) don't go back more than 20 years. Unless you are Koyfin, which goes back to 1969, so that is the date I've chosen! Fun fact, by selectively choosing the lows of 1971 a few years later as an entry point to buy SPGI, that $10k would turn into a cool $48 million today. Even Buffet missed that one! I wonder if he knows??
Some would argue that Morningstar is in Activation; after all, they provide analytics on mutual fund data. While their fund ratings are indeed an activation asset, their primary business is Distribution. The identifying characteristic of Distribution is that it does not have IP over the data it distributes. Fund data, like company disclosures, is a public good. Morningstar deals with the complexity of aggregating it from hundreds of sources, organizing it and making it accessible through a single end-point. This will become more evident through the post.
Unstructured reference data encompasses central bank policy statements and forward guidance, finance/treasury outlooks and projections, fiscal policy and debt management plans, systemic risks and stress testing outcomes, economic policies and trade agreements.
Yes, the $25bn is primarily transaction revenue, but the modern interpretation of the exchange is that data fees and transaction fees are inseparable (per one long, boring ESMA paper). One cannot exist without the other. Let's hope this doesn't lead exchanges to stop reporting data revenues separately
'Standardized' data here is a classification, not to be confused with the process of standardizing data in the transformation/organizing stage - the adjective vs verb form. While I'm at it, I use 'exchange' in the noun and verb form a bit later. And, of course, at the end excuse my use of 'return' in the noun form over the verb for a bit of misdirection in the title.
Some providers have monetized aggregation of estimates and equity ratings across analysts but have yet to attain universal acceptance/ standards. We'll explore in a dedicated post why equity research remains fragmented.
Now you know how you get free stock price information on Google, Yahoo Finance, MarketWatch, Investing.com, Tradingview or any of the hundred other websites catering to retail investors that show 15-minute delayed data.
There is a slight nuance here with consolidated tapes that various exchanges contribute to collectively. While this may reduce the power of a single exchange in the US from determining price, it doesn't necessarily reduce the pricing power of each exchange on their data feeds.
Cross-listing of securities, along with ATS, MTF, SIs and dark pools, does fragment liquidity per instrument. However, NBBO and RNMS ensure that the adverse effects of fragmented liquidity are addressed to some extent.
ROE for the three big (barely competing) US exchange groups – ICE, NDAQ & CME have hovered around 10% for the last 15+ years. Introduce real competition, and that quickly becomes unattractive.
What are credit ratings? Credit ratings offer an independent assessment of the credit risk of a fixed-income instrument. In plainer English, an independent body reviews the financial and business prospects of a company issuing a bond and informs its investors of the likelihood that that debt will meet its obligations, i.e., interest payments and principal return. The rating agency, as they are called, issues a rating from AAA+, indicating 99%+ likelihood of paying back debt, down to CCC indicating 50%+ likelihood of default on a 10 year time horizon, with D rating for in default. Ratings, hence, represent a probability of default. It can be applied at both the issuer level (corporates and governments) and the issue level (individual bonds, as firms have multiple outstanding debts of varying seniority).
Reducing functions have created other powerful data businesses – FICO for retail credit scores, AM Best for insurance data, CoreLogic for property data. I suspect more are in the works. Let me know if you have other examples.
Asset managers have to disclose how well they are managing your assets. To do this they undertake performance benchmarking by comparing their portfolio data with that of a benchmark. Getting access to a benchmark’s underlying data incurs a separate fee. Asset managers also purchase protection from outlier risk events, usually in the form of put contracts on the entire index (these are the most liquid). These instruments are synthetically created, and index providers charge a fee for the right to create an options contract on their index, even though the entire instrument creation process is done by someone else. Rarely do you find a business that can additional revenue for doing no additional work!
Thank you for the post. Interested in seeing startups doing LLM work for activation and ui complexities 👀
Thank you for this post (and the December post). Highlighted your work in my Alternative Data Weekly. I hope to drive more traffic and readers to this valuable content.